The Zero Resource Speech Challenge 2017
Summary
Task and intended goal
This challenge targets the unsupervised discovery of linguistic units from raw speech in an unknown language. As in the 2015 edition, it concerns two core components: the discovery of subword units (Track 1) and the discovery of word units (Track 2), respectively. For both tracks, the same evaluation metrics as in the former edition are used.
Discovering linguistic subword and word units from raw speech are key elements of any system that would provide speech services in an unknown language (e.g., keyword spotting, audio document classification or retrieval, language documentation, etc.), and also is an approximate model for what infants achieve during their first year of life. These tasks therefore deserve to be studied in their own right, and have been for many years [1-11].
The 2017 iteration introduces two key innovations:
- Generalization across Languages: What the challenge is after, is systems that can discover linguistic representations in any language. The participant’s task is to construct their system and tune their hyper-parameters so as to be robust across languages. The 2017 challenge therefore uses a classical training/test split, but at a higher level than usual: at the level of language corpora, not at the level of utterances. Specifically, it provides a development dataset (hyperparameter training set) made of three language corpora together with full train/test split, evaluation software and phone annotations, so that participants can fully train their systems, test them and tune their hyperparameters. Participants are encouraged to use cross validation so as to avoid overfitting on the three development languages. At this point, participants will register their hyperparameters and code. Once done, they will receive the surprise dataset (hyperparameter test set): two new languages in bare form (raw signals, no labels, no evaluation software) on which they can only run their code with the fixed set of registered hyperparameters. The results will be submitted to a website which will run and return the results of the evaluations. Each team will only be able to submit once (see Figure 1).
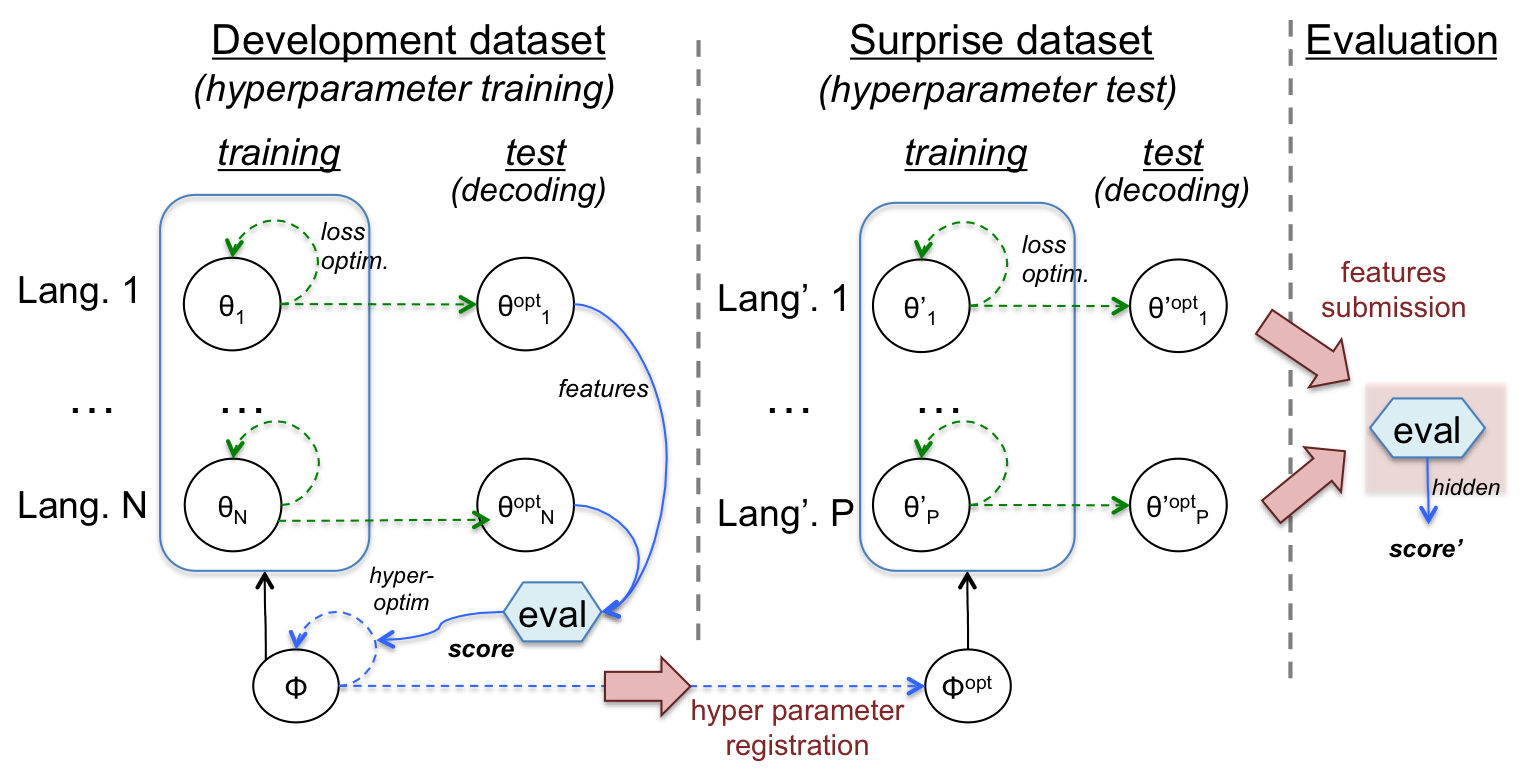
Figure 1. General setup of the Challenge.
- Speaker adaptation/invariance: In the previous challenge, most teams made little use of the speaker information provided. The possible reason was that there were not really enough data per speaker to enable the construction of speaker specific models or to use speaker adaptation techniques. Yet, in [15], it was shown that terms discovered in the baseline of Track 2 could be used to construct speaker invariant features, even though most of the terms were actually within speaker. Here, we will provide datasets and metrics geared towards using speaker adaptation techniques. Each language will be itself split in a train set and a test set at the level of speakers. The train set will be used for training the system’s parameters. It will incorporate a distribution of speakers that are intended to mimic those available in naturalistic autonomous situations (mimicking a power law, with few speakers speaking a lot–relatives, and a lot of speakers speaking little–outsiders) with explicit ID tags. In the test set, no training will take place, only decoding. The test set contains only new speakers in unknown number appearing in many small files of average size ranging from 1s to 2 min. The names of the files will be scrambled, and no ID tag will be provided. The only speaker information available is that each file contains only one speaker, enabling to measure the effect of speaker adaptation as a function of file size.
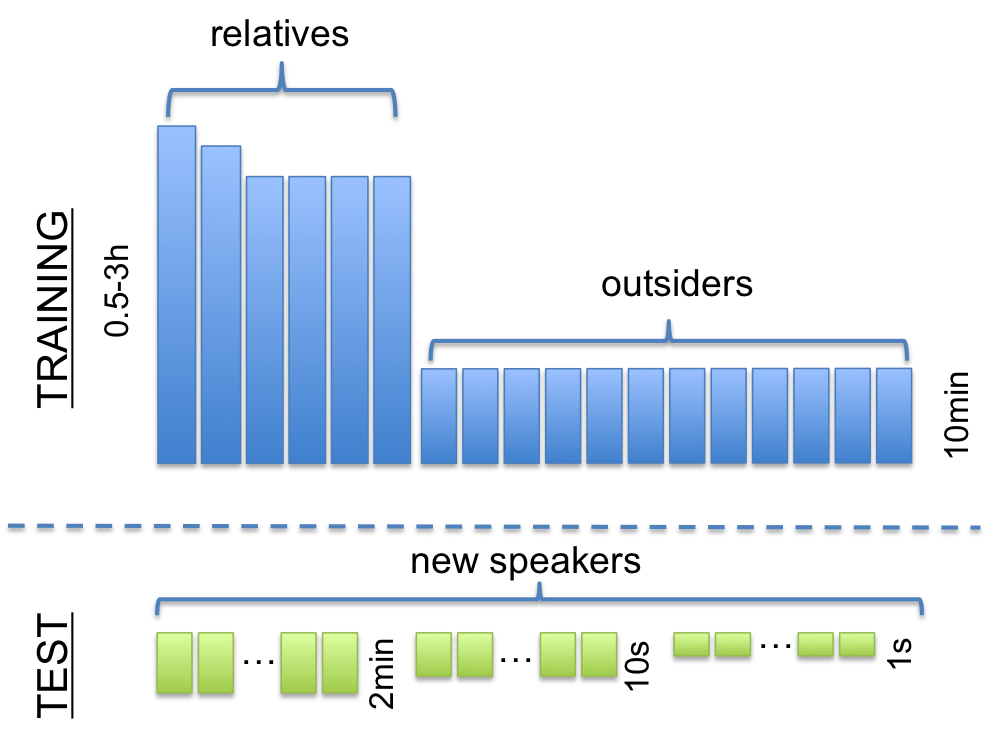
Figure 2 Distribution of the speakers into files in training and test.
In brief, the 2017 challenge aims at generalizable results, both across speakers and across languages. In addition, two more minor changes have been made:
-
Scale: Whereas the 2015 challenge used datasets between 2h30 and 5h, the 2017 one will range from 2h30m to 50h. This increment in scale should encourage contestants to optimize some of their algorithms, as well as to enable unsupervised techniques to reach better performance.
-
Evaluation metrics: Compared with the 2015 zero speech challenge, we plan to simplify the evaluation metrics (fewer) and propose new, application-based metrics in order to test the usefulness of the zero resource output for real life applications (see below).
Datasets
In the hypertraining, we will use 3 languages: English, French and Mandarin, and in the hypertest, 2 ‘surprise’ languages. All the datasets are read speech and are open source (either gathered from open source audio books, or open datasets). We have either used existing forced alignment or realigned these datasets ourselves. Table 1 shows the statistics of these languages.
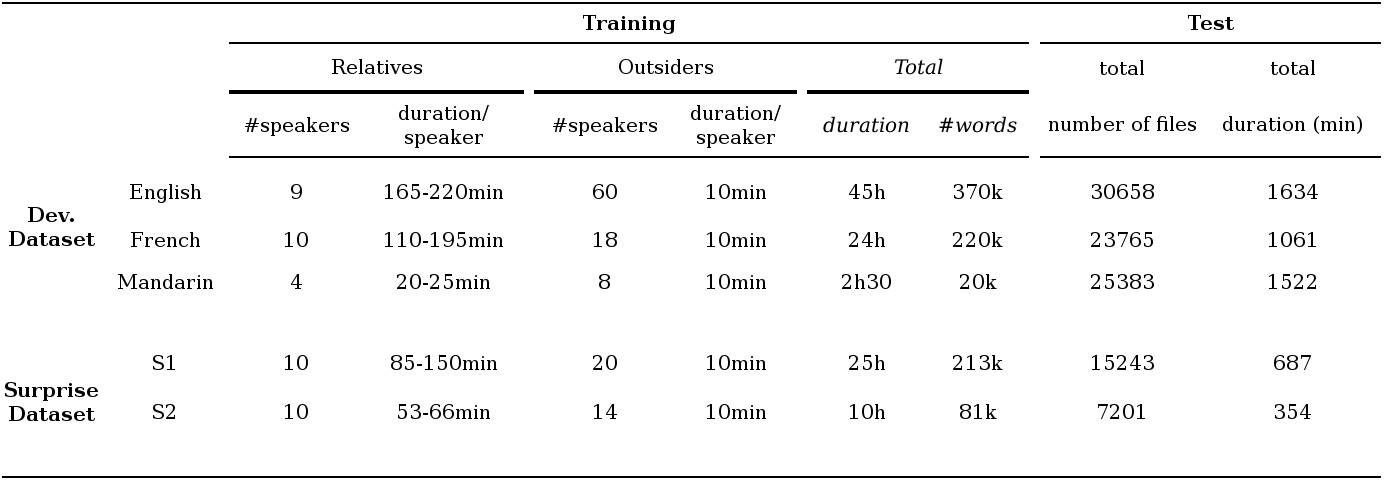
Table 1. Number of speakers and duration of each dataset.
Evaluation process
Track 1: unsupervised subword modeling. The aim in this task is to construct a representation of speech sounds which is robust to within- and between-talker variation and support word identification. The metric we use, as in the previous challenge is the ABX discriminability between phonemic minimal pairs (see [11,12]). For example, the ABX discriminability between the minimal pair ‘beg’ and ‘bag’ is defined as the probability that A and X are closer than B and X, where A and X are tokens of ‘beg’, and B a token of ‘bag’ (or vice versa), distance being defined as the DTW divergence of the representations of the tokens. Our global ABX discriminability score aggregates over the entire set of minimal pairs like ‘beg’-‘bag’ to be found in the test set. We analyze separately within- and between-talker discriminability.
Track 2: spoken term discovery. The aim in this task is the unsupervised discovery of ‘words’ in the audio defined as recurring speech fragments. The systems should take raw speech as input and output a list of speech fragments (start-end time stamps referring to the original audio file) together with a discrete label for category membership. The evaluation will use a reduced set of metrics compared to the preceding challenge, namely: NED and coverage, which measure the quality of the matching process, token F-score, which measures the quality of the segmentation, and type F-score, which measures the quality of the lexicon. The scores: boundary, gruping and matching, that were computed during the 2015’s Challenge are still available in the evaluation toolkit, however they won’t be used on the evaluation process.
Application metrics. These metrics will not be used to compare models but rather to illustrate the usefulness of zero resource technology for real life applications. These metrics will not require extra work from the participants, in the sense that they will automatically be computed and updated on our web site based on the outputs of Track 1 and 2 which will be fed them on baseline application systems. An application for Track 1 is Query by Example (QbE). A baseline QbE will be provided and run on the speech representation provided by the participants. The obtained score would be compared to baseline features (MFCC, supervised posteriorgrams and multilingual bottleneck features). An application for Track 2 is audio-based document clustering. (audio word2vec) Baselines will include the same tasks run on the text transcriptions of the corresponding audio files.
See the details in the Tabs Track 1 and Track 2.
Timeline
Thursday, July 6th (midnight UTC -12): initial ASRU submission deadline for papers describing challenge submissions
Thursday, July 13th (midnight UTC -12): ASRU paper modification deadline and final deadline for submitting Track 1/2 results (fea/txt) through Zenodo for evaluation
| Date | |
|---|---|
| 30-Dec-2016 | Release of development set (hyper training); website online |
| 30-May-2017 | Release of the surprise set (hyper test) and opening of results submission. |
| 6-Jul-2017 | ASRU abstract or paper submission deadline. |
| 13-Jul-2017 | Final date for submitting to ASRU the revised paper. |
| 31-Aug-2017 | Notification of paper acceptance. |
| 16-20 Dec-2017 | ASRU Conference. |
Scientific committee
-
Emmanuel Dupoux
-
Professor, Ecole des Hautes Etudes en Sciences Sociales, Paris
-
Computational modeling of language acquisition, psycholinguistics, infant language development, unsupervised learning of linguistic units
-
email: emmanuel.dupoux@gmail.com, website: http://www.lscp.net/persons/dupoux
-
-
Laurent Besacier
-
Professor, LIG, Univ. Grenoble Alpes (UGA)
-
Automatic speech recognition, processing low-resourced languages, acoustic modeling, speech data collection, machine-assisted language documentation
-
email: laurent.besacier@imag.fr, website: http://lig-membres.imag.fr/besacier/
-
-
Okko Rasanen
-
Docent, Aalto University, Finland
-
Cognitive modeling, human inspired machine learning and speech recognition
-
email: okko.rasanen@aalto.fi, website: http://users.spa.aalto.fi/orasanen/
-
-
Sharon Goldwater
-
Associate Professor, Institute for Language, Cognition and Computation, University of Edinburgh
-
Cognitive modeling, NLP, Speech processing
-
email: sgwater@inf.ed.ac.uk, website: http://homepages.inf.ed.ac.uk/sgwater/
-
-
Xavier Anguera
-
CTO & CSO ELSA
-
Query-by-example, spoken term discovery, acoustic modeling, zero resource speech technologies
-
email: xanguera@gmail.com, website: http://www.xavieranguera.com
-
Challenge Organizing Committee
-
Emmanuel Dupoux (Coordination) Researcher, EHESS, emmanuel.dupoux@gmail.com
-
Xavier Anguera (Datasets) CTO & CSO ELSA, xanguera@gmail.com
-
Laurent Besacier (Datasets) Professor, LIG, Univ. Grenoble Alpes (UGA), laurent.besacier@imag.fr
-
Ewan Dunbar (Organizer) Researcher, ENS, Paris emd@umd.edu
-
Neil Zeghidour (Organizer) Researcher, Facebook AI, Paris neil.zeghidour@gmail.com
-
Thomas Schatz (Organizer) Researcher, ENS, Paris thomas.schatz.1986@gmail.com
-
Xuan-Nga Cao (Datasets) Research Engineer, ENS, Paris ngafrance@gmail.com
-
Mathieu Bernard (Baselines and Toplines) Engineer, ENS, Paris mmathieubernardd@gmail.com
-
Julien Karadayi (Track 1) Engineer, ENS, Paris julien.karadayi@gmail.com
-
Juan Benjumea (Track 2) Engineer, ENS, Paris jubenjum@gmail.com
Sponsors
 Zero Speech Challenge 2015 is funded through an ERC grant to Emmanuel
Dupoux (see website).
Zero Speech Challenge 2015 is funded through an ERC grant to Emmanuel
Dupoux (see website).
References
Subword units/embeddings
-
[1] Badino, L., Canevari, C., Fadiga, L., & Metta, G. (2014). An auto-encoder based approach to unsupervised learning of subword units. In ICASSP.
-
[2] Huijbregts, M., McLaren, M., & van Leeuwen, D. (2011). Unsupervised acoustic sub-word unit detection for query-by-example spoken term detection. In ICASSP (pp. 4436-4439).
-
[3] Jansen, A., Thomas, S., & Hermansky, H. (2013). Weak top-down constraints for unsupervised acoustic model training. In ICASSP (pp. 8091-8095).
-
[4] Lee, C., & Glass, J. (2012). A nonparametric Bayesian approach to acoustic model discovery . In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers Volume 1 (pp. 40-49).
-
[5] Varadarajan, B., Khudanpur, S. & Dupoux, E. (2008). Unsupervised Learning of Acoustic Subword Units . In Proceedings of ACL-08: HLT, (pp 165-168).
-
[6] Synnaeve, G., Schatz, T & Dupoux, E. (2014). Phonetics embedding learning with side information. In IEEE:SLT.
-
[7] Siu, M., Gish, H., Chan, A., Belfield, W. & Lowe, S. (2014). Unsupervised training of an HMM-based self-organizing unit recognizer with applications to topic classification and keyword discovery. In Computer Speech & Language 28.1, (pp 210-223).
Spoken term discovery
-
[8] Jansen, A., & Van Durme, B. (2011). Efficient spoken term discovery using randomized algorithms . In IEEE ASRU Workshop (pp. 401-406).
-
[9] Muscariello, A., Gravier, G., & Bimbot, F. (2012). Unsupervised Motif Acquisition in Speech via Seeded Discovery and Template Matching Combination in ICASSP (Vol. 20,7, pp. 2031-2044).
-
[10] Park, A. S., & Glass, J. R. (2008). Unsupervised Pattern Discovery in Speech . In ICASSP, 16(1), 186-197.
-
[11] Zhang, Y., & Glass, J. R. (2010). Towards multi-speaker unsupervised speech pattern discovery. In ICASSP (pp. 4366-4369).
Evaluation metrics
-
[12] Schatz, T., Peddinti, V., Xuan-Nga, C., Bach, F., Hynek, H. & Dupoux, E. (2014). Evaluating speech features with the Minimal-Pair ABX task (II): Resistance to noise . In Interspeech.
-
[13] Schatz, T., Peddinti, V., Bach, F., Jansen, A., Hynek, H. & Dupoux, E. (2013). Evaluating speech features with the Minimal-Pair ABX task: Analysis of the classical MFC/PLP pipeline . In Interspeech (pp 1781-1785).
-
[14] Ludusan, B., Versteegh, M., Jansen, A., Gravier, G., Cao, X.N., Johnson, M. & Dupoux, E. (2014). Bridging the gap between speech technology and natural language processing: an evaluation toolbox for term discovery systems . In Proceedings of LREC.
Papers published from the Zero Resource Speech Challenge 2015
-
[15] R. Thiollière, E. Dunbar, G. Synnaeve, M. Versteegh, and E. Dupoux, “A hybrid dynamic time warping-deep neural network architecture for unsupervised acoustic modeling,” in INTERSPEECH-2015, 2015.
-
[16] L. Badino, A. Mereta, and L. Rosasco, “Discovering Discrete Subword Units with Binarized Autoencoders and Hidden-Markov-Model Encoders,” in 16th Annual Conference of the International Speech Communication Association, 2015.
-
[17] D. Renshaw, H. Kamper, A. Jansen, and S. Goldwater, “A Comparison of Neural Network Methods for Unsupervised Representation Learning on the Zero Resource Speech Challenge,” in Sixteenth Annual Conference of the International Speech Communication Association, 2015.
-
[18] W. Agenbag and T. Niesler, “Automatic Segmentation and Clustering of Speech Using Sparse Coding and Metaheuristic Search,” in Sixteenth Annual Conference of the International Speech Communication Association, 2015.
-
[19] H. Chen, C.-C. Leung, L. Xie, B. Ma, and H. Li, “Parallel Inference of Dirichlet Process Gaussian Mixture Models for Unsupervised Acoustic Modeling: A Feasibility Study,” in Sixteenth Annual Conference of the International Speech Communication Association, 2015.
-
[20] P. Baljekar, S. Sitaram, P. K. Muthukumar, and A. W. Black, “Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing,” in Sixteenth Annual Conference of the International Speech Communication Association, 2015.
-
[21] O. Räsänen, G. Doyle, and M. C. Frank, “Unsupervised word discovery from speech using automatic segmentation into syllable-like units,” in Proceedings of Interspeech, 2015.
-
[22] V. Lyzinski, G. Sell, and A. Jansen, “An Evaluation of Graph Clustering Methods for Unsupervised Term Discovery,” in Sixteenth Annual Conference of the International Speech Communication Association, 2015.
-
[23] Cheng-Tao, C. et al. (2015). “An iterative deep learning framework for unsupervised discovery of speech features and linguistic units with applications on spoken term detection.” IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU).
-
[24] Ondel, L, Burget, L. and Černocký, J. “Variational Inference for Acoustic Unit Discovery.” Procedia Computer Science 81 (2016): 80-86.
-
[25] Heck, M., Sakti, S., and Nakamura, S. “Unsupervised Linear Discriminant Analysis for Supporting DPGMM Clustering in the Zero Resource Scenario.” Procedia Computer Science 81 (2016): 73-79.
-
[26] Herman, K., Jansen, A. and Goldwater, S. “A segmental framework for fully-unsupervised large-vocabulary speech recognition.” arXiv preprint arXiv:1606.06950 (2016).
-
[27] Zeghidour, N., Synnaeve, G., Versteegh, M. & Dupoux, E. (2016). A Deep Scattering Spectrum - Deep Siamese Network Pipeline For Unsupervised Acoustic Modeling. In ICASSP-2016.
Corpora
-
[28] French corpus: Selection of book chapters from librivox - https://librivox.org/
-
[29] Chinese corpus: Dong Wang, Xuewei Zhang, Zhiyong Zhang, “THCHS-30: A Free Chinese Speech Corpus”, 2015, http://arxiv.org/abs/1512.01882
-
[30] English corpus: V. Panayotov, G. Chen, D. Povey and S. Khudanpur, “Librispeech: An ASR corpus based on public domain audio books,” 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, 2015, pp. 5206-5210.
