
tl;dr
- The objective of the Zero Resource Speech Challenge (ZRC) series is to enable researchers to build a spoken dialogue system directly from raw audio recordings (no text, no labels!)
- This is difficult, so ZRC breaks down the problem into more manageable subtasks, and provides metrics for cumulative progress
- It currently supports 4 subtasks:
The ZRC series is now open on a rolling basis. Here, you’ll find here step-by-step guides on how to submit your own contributions and appear on the leaderboard! You’ll also be able to download past results to do your own analysis and model comparison.
What?
For hearing humans, speech is the primary form of communication. Most spoken languages have little or no associated textual resources, and in all cultures, young children learn to speak before they learn to read ( Citation: Dupoux, 2018 Dupoux, E. (2018). Cognitive science in the era of artificial intelligence: A roadmap for reverse-engineering the infant language-learner. Cognition, 173. 43–59. Retrieved from https://arxiv.org/abs/1607.08723 ; Citation: Bavin, 2009 Bavin, E. (2009). The Cambridge handbook of child language. Cambridge University Press. Retrieved from http://site.ebrary.com/id/10303044 ) . Yet, current language technology is overwhelmingly based on text. Even spoken dialogue systems are based on text (using ASR and TTS to convert speech to text and back to speech, Figure 1a). Could we get rid of text and build language processing from raw audio?
Why?
- It is an interesting self-supervised machine learning problem.
- It would open up applications for thousands of languages that are mostly or entirely unwritten, making AI more inclusive.
- Even in “high resource” languages, speech conveys aspects of language poorly represented in text (prosody, emotional and non-verbal vocalizations, oral expressions, etc). Speech-based systems could be more expressive than text-based ones.
- Self-supervised systems could provide predictive models of language development in a normal or abnormal setting (dyslexia, etc).
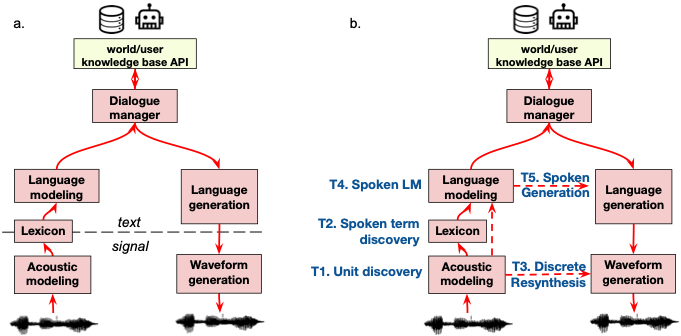
Figure. 1. a. Traditional pipeline for a spoken assistant based on textual resources. b. Pipeline and tasks for the Zero Resource Speech Benchmark.
How?
The ZRC series addresses two interlocking research problems: the task problem and the evaluation problem.
The task problem is to break down the overall objective into a series of well-defined sub-problems.
The ZRC series follows the general architecture in Figure 1b: the acoustic model, lexicon, language model, waveform generation, and so on. But instead of using phonemes, characters or words as an intermediate representation, the components develop their own latent representations. For instance, instead of letters, the acoustic model outputs “acoustic units” which may or may not be discrete.
This gives rise to the following tasks:
- Task 1: Acoustic Unit Discovery
- Task 2: Spoken Term Discovery
- Task 3: Unsupervised Discrete Resynthesis
- Task 4: Spoken Language Modeling
These are the textless counterparts of well-known tasks: (Task 1) phone recognition; (Task 2) word recognition (i.e., ASR); (Task 3) TTS; and (Task 4) Language Modeling. (Task 5 is currently not supported.)
The evaluation problem is to define metrics that enable model comparison and cumulative progress.
In the ZRC series, we use zero-shot probe tasks that are inspired by human psycholinguistics, and which require no model retraining and reflect more directly the quality of the latent representations than if we were to train a classifier.
For each task, zero-shot metrics were developed that probe for the different levels of linguistic knowledge learned by the system. They only require the extraction of information readily available across systems (embeddings, pseudo-probabilities). See the sub-pages for each task and ( Citation: Dunbar, Hamilakis & al., 2022 Dunbar, E., Hamilakis, N. & Dupoux, E. (2022). Self-supervised language learning from raw audio: Lessons from the zero resource speech challenge series. IEEE Journal of Special Topics in Signal Processing, 16(6). 1211–1226. Retrieved from https://arxiv.org/abs/2005.12656 ) for more information.
Cited
- Bavin (2009)
- Bavin, E. (2009). The Cambridge handbook of child language. Cambridge University Press. Retrieved from http://site.ebrary.com/id/10303044
- Dunbar, Hamilakis & Dupoux (2022)
- Dunbar, E., Hamilakis, N. & Dupoux, E. (2022). Self-supervised language learning from raw audio: Lessons from the zero resource speech challenge series. IEEE Journal of Special Topics in Signal Processing, 16(6). 1211–1226. Retrieved from https://arxiv.org/abs/2005.12656
- Dupoux (2018)
- Dupoux, E. (2018). Cognitive science in the era of artificial intelligence: A roadmap for reverse-engineering the infant language-learner. Cognition, 173. 43–59. Retrieved from https://arxiv.org/abs/1607.08723
