Zerospeech 2015
Summary
Spoken term discovery
Spoken term discovery can be logically broken down into a series of 3 operations, which can be all evaluated independently (see Figure 1). The first step consists in matching pairs of stretches of speech on the basis of their global similarity. The second step consists in clustering the matching pairs, thereby building a library of classes with potentially many instances. This is equivalent to building a lexicon. In the third step, the system can use its acquired classes to parse the continuous stream into candidate tokens and boundaries. Some systems may only implement some of these steps, others may do them simultaneously rather than sequentially. The metric below have been devised to enable comparisons between these different systems by evaluating separately these logically distinct steps.
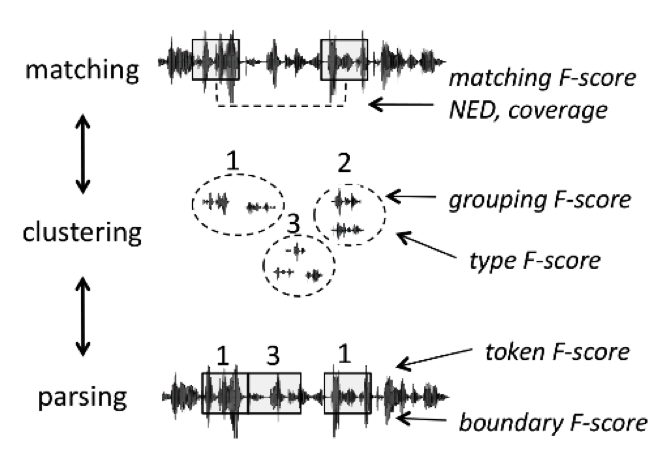
Figure 1. term discovery principles
Evaluation metrics
All of our metric assume a time aligned transcription, where $T_{i,j}$ is the (phoneme) transcription corresponding to the speech fragment designed by the pair of indices $\langle i,j \rangle$ (i.e., the speech fragment between frame $i$ and $j$ ). If the left or right edge of the fragment contains part of a phoneme, that phoneme is included in the transcription if is corresponds to more than more than 30ms or more than 50% of it’s duration.
We first define the set related to the output of the discovery algorithm:
- $C_{disc}$: the set of discovered clusters (a cluster being a set of fragments with the same category name).
From these, we can derive:
-
$F_{disc}$: the set of discovered fragments, $F_{disc} = { f | f \in c , c \in C_{disc} }$
-
$P_{disc}$: the set of non overlapping discovered pairs, $P_{disc} = { {a,b} | a \in c, b \in c, \neg \textrm{overlap}(a,b), c \in C_{disc} }$
-
$P_{disc^*}$: the set of pairwise substring completion of $P_{disc}$, which mean that we compute all of the possible minimal path realignments of the two strings, and extract all of the substrings pairs along the path (e.g., for fragment pair $\langle abcd, efg \rangle$: $\langle abc, efg \rangle$, $\langle ab,ef \rangle$, $\langle bc, fg \rangle$, $\langle bcd, efg \rangle$, etc).
-
$B_{disc}$: the set of discovered fragment boundaries (boundaries are defined in terms of $i$, the index of the nearest phoneme boundary in the transcription if it is less than 30ms away, and -1 (wrong boundary) otherwise)
Note:
Two fragments a and b overlap if they share more than half of their temporal extension.
Next, we define the gold sets:
-
$F_{all}$: the set of all possible fragments of size between 3 and 20 phonemes in the corpus.
-
$P_{all}$: the set of all possible non overlapping matching fragment pairs. $P_{all}={ {a,b }\in F_{all} \times F_{all} | T_{a} = T_{b}, \neg \textrm{overlap}(a,b)}$.
-
$F_{goldLex}$: the set of fragments corresponding to the corpus transcribed at the word level (gold transcription).
-
$P_{goldLex}$: the set of matching fragments pairs from the $F_{goldLex}$.
-
$B_{gold}$: the set of boundaries in the parsed corpus.
Most of our measures are defined in terms of Precision, Recall and F-score. Precision is the probability that an element in a discovered set of entities belongs to the gold set, and Recall the probability that a gold entity belongs to the discovered set. The F-score is the harmonic mean between Precision and Recall.
-
$Precision_{disc,gold} = | disc \cap gold | / | disc |$
-
$Recall_{disc,gold} = | disc \cap gold | / | gold |$
-
$F-Score_{disc,gold} = 2 / (1/Precision_{disc,gold} + 1/Recall_{disc,gold})$
Matching quality
Many spoken term discovery systems incorporate a step whereby fragments of speech are realigned and compared. Matching quality measures the accuraty of this process. Here, we use two kinds of metrics for evaluating this: NED/Coverage, and Matching F-score.
NED and Coverage are quick to compute and give a qualitative estimate of the matching step. Ned is the normalised edit distance; it is equal to zero when a pair of fragments have exactly the same transcription, and 1 when they differ in all phonemes. Coverage is the fraction of corpus that contain matching pairs that has been discovered.
$$ \textrm{NED} = \sum_{\langle x, y\rangle \in P_{disc}} \frac{\textrm{ned}(x, y)}{|P_{disc}|} $$ $$ \textrm{Coverage} = \frac{|\textrm{cover}(P_{disc})|}{|\textrm{cover}(P_{all})|} $$
where
$$ \textrm{ned}(\langle i, j \rangle, \langle k, l \rangle) = \frac{\textrm{Levenshtein}(T_{i,j}, T_{k,l})}{\textrm{max}(j-i+1,k-l+1)} $$ $$ \textrm{cover}(P) = \bigcup_{\langle i, j \rangle \in \textrm{flat}(P)}[i, j] $$ $$ \textrm{flat}(P) = {p|\exists q:{p,q}\in P} $$
The Matching metrics (precision, recall and F-score) is much more exhaustive, but requires considerably more computation. It compares $X=P_{disc^*}$ the set of discovered pairs (with substring completion) to $Y=P_{all}$ the set of all possible gold pairs. The precision and recall are computed over each type of pairs, and averaged after reweighting by the frequency of the pair.
$$ \text { Matching precision }=\sum_{t \in \text { types }\left(\text { flat }\left(P_{\text {disc* }}\right)\right)} f_{\text {req }}\left(t, P_{\text {disc* }}{ }\right) \frac{\left|\operatorname{match}\left(t, P_{\text {disc* }} \cdot \cap P_{\text {all }}\right)\right|}{\left|\operatorname{match}\left(t, P_{\text {disc* }}\right)\right|} $$
$$ \textrm{Matching recall} = \sum_{t\in\textrm{types}(\textrm{flat}(P_{all}))} freq(t, P_{all}) \frac{|\textrm{match}(t, P_{disc^*} \cap P_{all})|}{|\textrm{match}(t, P_{all})|} $$
where
$$ \textrm{types}(F) = {T_{i,j}|\langle i, j\rangle\in F} $$ $$ \textrm{match}(t,P) = {\langle i, j\rangle \in\textrm{flat}(P)|T_{i,j}=t} $$ $$ freq(t,P) = \frac{|\textrm{match}(t,P)|}{|\textrm{flat}(P)|} $$
Clustering Quality
Clustering quality is evaluated using two metrics. The first metrics (Grouping precision, recall and F-score) computes the intrinsic quality of the clusters in terms of their phonetic composition. This score is equivalent to the purity and inverse purity scores used for evaluating clustering. As the Matching score, it is computed over pairs, but contrary to the Matching scores, it focusses on the covered part of the corpus.
$$ \textrm{Grouping precision} = \sum_{t\in\textrm{types}(\textrm{flat}(P_{clus}))} freq(t, P_{clus}) \frac{|\textrm{match}(t, P_{clus} \cap P_{goldclus})|}{|\textrm{match}(t, P_{clus})|} $$ $$ \textrm{Grouping recall} = \sum_{t\in\textrm{types}(\textrm{flat}(P_{goldclus}))} freq(t, P_{goldclus}) \frac{|\textrm{match}(t, P_{clus} \cap P_{goldclus})|}{|\textrm{match}(t, P_{goldclus})|} $$
where
$$ P_{clus} = { \langle \langle i, j\rangle , \langle k, l \rangle\rangle | \exists c\in C_{disc},\langle i, j\rangle\in c \wedge \langle k, l\rangle\in c } $$ $$ P_{goldclus} = { \langle \langle i, j\rangle , \langle k, l \rangle\rangle | \exists c_1,c_2\in C_{disc}:\langle i, j\rangle\in c_1 \wedge \langle k, l\rangle\in c_2 \wedge T_{i,j}=T_{k,l} \wedge [i,j] \cap [k,l] = \varnothing } $$
The second metrics (Type precision, recall and F-score) takes as the gold cluster set the true lexicon and is therefore much more demanding. Indeed, a system could have very pure clusters, but could systematically missegment words. Since a discovered cluster could have several transcriptions, we use all of them (rather than using some kind of centroid).
$$ \textrm{Type precision} = \frac{|\textrm{types}(F_{disc}) \cap \textrm{types}(F_{goldLex})|} {|\textrm{types}(F_{disc})|} $$ $$ \textrm{Type recall} = \frac{|\textrm{types}(F_{disc}) \cap \textrm{types}(F_{goldLex})|} {|\textrm{types}(F_{goldLex})|} $$
Parsing Quality
Parsing quality is evaluated using two metrics. The first one (Token precision, recall and F-score) evaluates how many of the word tokens were correctly segmented ($X = F_{disc}$, $Y = F_{goldLex}$). The second one (Boundary precision, recall and F-score) evaluates how many of the gold word boundaries were found ($X = B_{disc}$, $Y = B_{gold}$). These two metrics are typically correlated, but researchers typically use the first. We provide Boundary metrics for completeness, and also to enable system diagnostic.
$$ \textrm{Token precision} = \frac{|F_{disc}\cap F_{goldLex}|}{|F_{disc}|} $$ $$ \textrm{Token recall} = \frac{|F_{disc}\cap F_{goldLex}|}{|F_{goldLex}|} $$ $$ \textrm{Boundary precision} = \frac{|B_{disc}\cap B_{gold}|}{|B_{disc}|} $$ $$ \textrm{Boundary recall} = \frac{|B_{disc}\cap B_{gold}|}{|B_{gold}|} $$
The details of these metrics are given in the Ludusan et al (2014) paper. The only divergence between this paper and the present measures, is that contrary to the paper, we compute these scores on the entirety of the corpus, rather than on the covered corpus. It is necessary to do this if we want to compare systems that will cover different subsets of the corpus. In the implementation for the challenge, we use a subsampling scheme whereby the corpus is cut into 10 equal parts and each metric is computed on each of the subsample separately and then averaged. This enables the computation to be more tractable (especially for the matching metric which requires substring completion), and also to provide a standard deviation measure for each metric. We also provide, in addition to each metric ran on the entire corpus, the same metric restricted to within talker matches. This is to enable the evaluation of systems that are specialized in within talker spoken term discovery.
