Leaderboards
Contents
Since 2015, several approaches have been taken to Task 1, and even though the performances are increasing, there is still a lot to be done (see the Leaderboard for more detailed results).
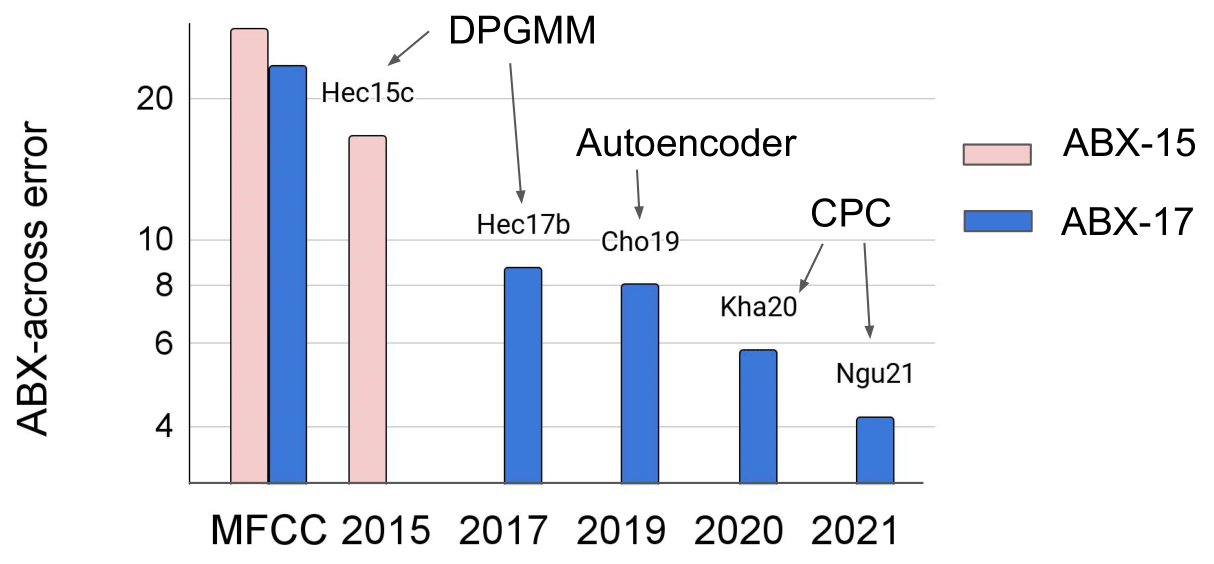
Figure 1. ZR Task 1 results on English ABX test sets (ABX-15: Conversational speech--Buckeye; ABX-17: Audiobooks--LibriVox). The left two scores are on MFCC representations. The right two scores have been trained on Librispeech 960.
More recently, Hallap et al (2022) examined in detail whether systems learned context-dependent allophone representations or something more like context-independent phoneme representations - now available in the ABX-LS benchmark (see below for detailed results).
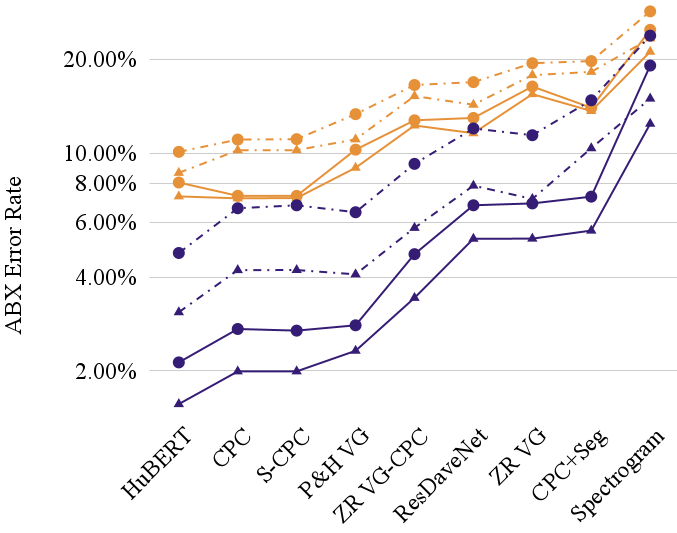
Figure 2. ZR Task 1 results on English ABX-LS test sets showing the gap between context-specific (purple: better) and context-independent (orange: worse) ABX scores. Dotted vs solid lines represent the clean (solid) versus other (dotted) test sets, and the shape represents within- (triangle) versus across- (circle) speaker conditions.
The results, shown in Figure 2, demonstrate that ABX tests which do not control for the phonological context (e.g., comparing the centre phone of the word cat /kæt/ with the centre phone of the word dog /dɔɡ/ ) show much poorer results with current systems (indicated in orange in the graph) than when the context is controlled (e.g., comparing the centre phone of cat versus cot /kɔt/) as indicated in purple - the error rate increases by a factor of roughly 400% in some cases! This is a much greater penalty than is seen for within- versus across-speaker (triangle versus circle) or for the clean versus other subsets of LibriSpeech (solid versus dotted). This suggests that context-independence of the learned units is still relatively poor.
ABX-15 Leaderboard
| English | Xitsonga | ||||||
|---|---|---|---|---|---|---|---|
| # | Author | Model ID | across | within | across | within | |
ABX-17 Leaderboard
| English | French | Mandarin | German | Wolof | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1s | 10s | 120s | 1s | 10s | 120s | 1s | 10s | 120s | 1s | 10s | 120s | 1s | 10s | 120s | |||||||||||||||||||
| # | Author | Model ID | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | |
| # | Author | Model ID | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | A | W | |
| 1s | 10s | 120s | 1s | 10s | 120s | 1s | 10s | 120s | 1s | 10s | 120s | 1s | 10s | 120s | |||||||||||||||||||
| English | French | Mandarin | German | Wolof | |||||||||||||||||||||||||||||
ABX-LS Leaderboard
-
AS: Across Speaker
-
WS: Within Speaker
| granularity | triphone-based (Classic) | phoneme-based | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| context | within | within | any | ||||||||||||||
| sub-set | clean | other | clean | other | clean | other | |||||||||||
| # | Details | Author | Model ID | Budget | AS | WS | AS | WS | AS | WS | AS | WS | AS | WS | AS | WS | |
