Benchmarks & Datasets
Summary
Introduction
Participants are requested to run each test sentence in their system, and extract two type of representations. At the very end of their pipeline, participants should collect a resynthesized wav file. In the middle of the pipeline, participants should extract a sequence of vectors corresponding to the system’s embedding of the test sentence at the entry point to the synthesis component. The embedding which is passed to the decoder must be submitted. Additionally, two additional representations may be submitted for evaluation, from earlier or later steps in the system’s pipeline.
The most general form for the embedding is a real valued matrix,
with the rows corresponding to the time axis and the columns to the
dimensions of a real valued vector. The low bit-rate constraint
(see below) will militate strongly in favour of a small, finite set of
quantized units. One possibility, similar to the symbolic “text” in a
classical TTS system, is a one-hot representation, with each “symbol”
being coded as a 1 on its own dimension. Representations are not
limited to one-hot representations, as many systems (for example,
end-to-end DNN systems) may wish to take useful advantage of the
internal structure of the numerical embedding space (but, to reduce
the bitrate, it is nevertheless advisable to quantize to a small
discrete subset, of numerical “symbols”). Conceptually, a
d-dimensional vector submitted as an embedding may thus be of at
least two types:
-
$d$ -dimensional 1-hot vectors (zeroes everywhere except for a 1 in one dimension) representing the $d$ discrete “symbols” discovered by the unit discovery system
-
$d$ -dimensional continuous valued embedding vectors, representing some transformation of the acoustic input
The file format, however, does not distinguish between these cases. The embedding file will be provided in simple text format (ASCII), one line per row (separated by newlines), each column being a numerical value, columns separated by exactly one space. The number of rows is not fixed: while you may use a fixed frame rate, no notion of “frame” is presupposed by any of the evaluations, so the length of the sequence of vectors for a given file can be whatever the encoding component of the system deems it to be. The matrix format is unaffected by this choice of representation, and the evaluation software will be applied irrespective of this distinction.
For the bitrate computation, the vectors will be processed as a single character string: a dictionary of all of the possible values of the symbolic vectors will be constructed over the entire test set, and the index to the dictionary will be used in place of the original value. This will be used to calculate the number of bits transmitted over the duration of the test set, by calculating the entropy of the symbolic vector distribution (average number of bits transmitted per vector) and multiplying by the total number of vectors. Be careful! We use the term symbolic vectors to remind you that the vectors should ideally belong to a small dictionary of possible values. We will automatically construct this dictionary using the character strings as they appear in the file. This means that very close vectors ‘1.00000000 -1.0000000’ and ‘1.00000001 -1.0000001’ will be considered distinct. (For that matter, even ‘1 1’ and ‘1.0 1.0’ will be considered different, because the character strings are different). Therefore, make sure that the numeric values of the vectors are formatted consistently, otherwise you will be penalized with a higher bitrate than you intended.
The two sets of output files (embedding and waveform) will be evaluated separately. The symbolic output will be analyzed using two metrics:
Bit rate.
Here, we assume that the entire set of audio in the test set corresponds to a sequence of vectors $U$ of length $P$ : $U=[s_1, ..., s_P]$ . The bit rate for $U$ is then $B(U)=\frac{P. \sum_{i=1}^{P} p(s_i)\,log_{2}\,p(s_i)}{D}$ , where $p(s_{i})$ is the probability of symbol $s_i$ The numerator of $B(U)$ is $P$ times the entropy of the symbols, which gives the ideal number of bits needed to transmit the sequence of symbols $s_{1:P}$ . In order to obtain a bitrate, we divide by $D$ , the total duration of $U$ in seconds. Note that a fixed frame rate transcription may have a higher bitrate than a ’textual’ representation due to the repetition of symbols across frames. For instance, the bit rate of a 5 ms framewise gold phonetic transcription is around 450 bits/sec and that of a ’textual’ transcription is 60 bits/sec. This indicates that there is a tradeoff between the bitrate and the detail of the information provided to the TTS system, both in number of symbols and in temporal information.
Unit quality.
Since it is unknown whether the
discovered representations correspond to large or small linguistic
units (phone states, phonemes, features, syllables, etc.), we
evaluate this with a theory-neutral score, a machine ABX score, as
in the previous Zero Resource challenges [23]. For a frame-wise representation,
the machine-ABX discriminability between ‘beg’ and ‘bag’ is defined as the probability that A and X are closer
than B and X, where A and X are tokens of ‘beg’, and B a token of
‘bag’ (or vice versa), and X is uttered by a different speaker than A and B.
The choice of the appropriate distance measure is up to the researcher.
In previous challenges, we used by default the average frame-wise cosine divergence of the representations of the tokens along a DTW-realigned path.
The global ABX discriminability score aggregates over the entire set of minimal pairs like ‘beg’-‘bag’ to be found in
the test set. We provide in the evaluation package the option of instead using a normalized Levenshtein edit distance.
We give ABX scores as error rates. The ABX score of the gold phonetic
transcriptions is 0 (perfect), since A, B and X are determined to be “the same” or “different” based on the gold transcription.
Note:
Because the symbolic embeddings submitted in this challenge typically do not have durations or temporal alignment, we cannot compute the ABX scores in the same way as in the previous two challenges (which were relying on alignements to extract the features of triphones like ‘beg’ or ‘bag’ from entire utterances). Here, we systematically extracted all the triphones as waveforms and provided them as small files (in addition to the original uncut sentence). This is why the test dataset contains many small files.
Synthesis accuracy and quality.
The synthesized wave files will be evaluated by humans (native speakers of the target language) using three judgment tasks.
-
Judges will evaluate intelligibility by transcribing orthographically the synthesized sentence. Each transcription will then be compared with the gold transcription using the edit distance, yielding a character error rate (character-wise, to take into account possible orthographic variants or phone-level susbtitutions).
-
Judges will evaluate the speaker similarity using a subjective 1 to 5 scale. They will be presented with a sentence from the original target voice, another sentence by the source voice, and then yet another resynthesized sentence by one of the system. A response of 1 means that the resynthesized sentence has a voice very similar to the target voice, 5 that it has a voice very similar to the source.
-
Judges will evaluate the overall quality of the synthesis on a 1 to 5 scale, yielding a Mean Opinion Score (MOS).
For the development language, we will provide all of the evaluation software (bitrate and ABX), so that participants can test for the adequacy of their full pipeline. We will not provide human evaluations, but we will provide a mock experiment reproducing the conditions of the human judgemnts, that participants can run on themselves, so that they can get a sense of what the final evaluation on the test set will look like.
For the test language, only audio will be provided (plus the bitrate evaluation software). All human and ABX evaluations will be run automatically when the participants will have submitted their annotations and wav files through the submission portal. An automatic leaderboard will then appear on the challenge’s website.
TTS0-19
TTS0-LSLJ
Datasets
We provide datasets for two languages, one for development, one for test.
The development language is English. The test language is a surprise Austronesian language for which much fewer resources are available. Only the development language is to be used for model development and hyperparameter tuning. The exact same model and hyperparameters must be used to train on the test language. In other words, the results on the surprise language must be the output of applying exactly the same training procedure as the one applied to the development corpus; all hyperparameter selection must be done beforehand, on the development corpus, or automated and integrated into training. The goal is to build a system that generalizes out of the box, as well as possible, to new languages. Participants will treat English as if it were a low-resource language, and refrain from using preexisting resources (ASR or TTS systems pretrained on other English datasets are banned). The aim is to only use the training datasets provided for this challenge. Exploration and novel algorithms are to be rewarded: no number hacking here!
Four datasets are be provided for each language:
-
the Voice Dataset contains one or two talkers, for around 2h of speech per talker. It is intended to build an acoustic model of the target voice for speech synthesis.
-
The Unit Discovery Dataset contains read text from 100 speakers, with around 10 minutes talk from each speaker. These are intended to allow for the construction of acoustic units.
-
The Optional Parallel Dataset contains around 10 minutes of parallel spoken utterances from the Target Voice and from other speakers. This dataset is optional. It is intended to fine tune the task of voice conversion. Systems that use this dataset will be evaluated in a separate ranking.
-
The Test Dataset contains new utterances by novel speakers. For each utterance, the proposed system has to generate a transcription using discovered subword units, and resynthesize the utterance into a waveform in the target voice(s), only using the computed transcription.
The Voice Dataset in English contains two voices (one male, one female). This is intended to cross-validate the TTS part of the system on these two voices (to avoid overfitting).
| # speakers | # utterances | Duration (VAD) | ||
|---|---|---|---|---|
| Development Language (English) | ||||
| Train Voice Dataset | 1 Male | 970 | 2h | |
| 1 Female | 2563 | 2h40 | ||
| Train Unit Dataset | 100 | 5941 [16-80 by speaker] | 15h40 [2-11min by speaker] | |
| Train Parallel Dataset | 10+ (*) | 1 male | 92 | 4.3min |
| 1 female | 98 | 4.5min | ||
| Test Dataset | 24 | 455 [6-20 by speaker] | 28min [1-4min by speaker] | |
| Test Language (surprise Austronesian) | ||||
| Train Voice Dataset | 1 Female | 1862 | 1h30 | |
| Train Unit Dataset | 112 | 15340 [81-164 by speaker] | 15h | |
| Train Parallel Dataset | 15 + 1 Female | 150 | 8min | |
| Test Dataset | 15 | 405 [10-30 by speaker] | 29min [1-3min by speaker] | |
* : For the Train Parallel Dataset, there are 10 new speakers reading phrases from each speaker from the Train Voice Dataset.
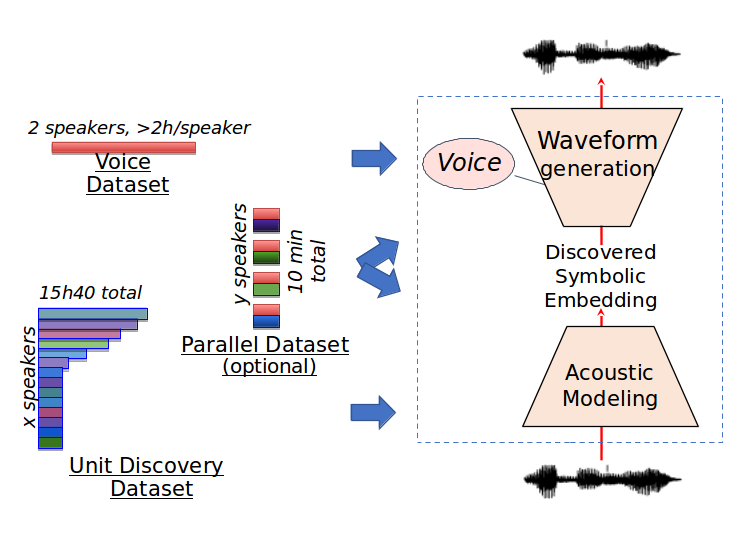
Figure 1b. Summary of the datasets used in the ZeroSpeech2019 Challenge. The Unit Discovery dataset provides a variety of speakers and is used for unsupervised acoustic modeling (i.e., to discover speaker-invariant, language-specific subword discrete units–symbolic embeddings). The Voice dataset is used to train the synthesizer. The Parallel dataset is for fine tuning the two subsystems. These datasets consist in raw waveforms (no text, no label beyond speaker ID).
