Discrete Resynthesis / TTS without T
Contents
Task & Goal
Here, we investigate a task which is similar to what infants may do when they repeat a word or a sentence: they encode the signal into some representation, and then reproduce the same content in their own voice.
Defined like this, the task is already known as voice cloning or voice transfer, and it can be performed at a rather low level by introducing a target speaker embedding in the decoder part of a simple encoder-decoder architecture. Here, however, we add the constraint that there be a discrete bottleneck between the encoder and decoder, and we measure the bitrate of the encoding.
In other words, we ask participants to use discovered acoustic units instead of phonemes, and we push these units to approach the bitrate of phonemic transcription. Prior to the ZRC, ( Citation: Scharenborg, Besacier & al., 2018 Scharenborg, O., Besacier, L., Black, A., Hasegawa-Johnson, M., Metze, F., Neubig, G., Stüker, S., Godard, P., Müller, M., Ondel, L., Palaskar, S., Arthur, P., Ciannella, F., Du, M., Larsen, E., Merkx, D., Riad, R., Wang, L. & Dupoux, E. (2018). Linguistic unit discovery from multi-modal inputs in unwritten languages: Summary of the “speaking rosetta” JSALT 2017 workshop. IEEE. ) demonstrated the feasibility of unsupervised discrete resynthesis. Furthermore, some of the models in Task 1 (Bad15a–c,Cho19) already used a similar discrete bottleneck auto-encoder architecture, although they did not evaluate the quality of the reconstruction nor the bitrate of the representation.
Participants on this task are provided with a unit dataset from multiple speakers used to discover discrete units, and a voice dataset to train a synthesizer for the target voice taking the units as input. The test dataset consists of novel utterances by unseen speakers, which must be resynthesized in the target voice. Participants submit both the acoustic unit representation and the resynthesis for evaluation. As for the acoustic units, they are evaluated in terms of their bitrate, where each unique embedding value is counted as a single symbol type. Bitrate is calculated as the entropy of the symbols divided by the average duration of the symbols.
The quality of the resynthesis is assessed by using human evaluations (principally Mean Opinion Scores, MOS). For comparison with other tasks, the ABX scores for the discrete codes are also calculated1.
The performance on the downstream task was overall quite good, with several systems achieving better resynthesis than the text-based top-line. As shown in Figure 5, there is a general tradeoff between synthesis quality and bitrate, which held both in the dev language (English) and in the heldout surprise test language (Indonesian).
As shown by the black point in the figure (the decoded output of a simple phone recognizer), phonemic transcription is a highly-compressed representation of speech which is excellent for this task (the middling MOS scores are attributable to the fact that the out-of-the-box ASR and TTS were not optimized to the task).
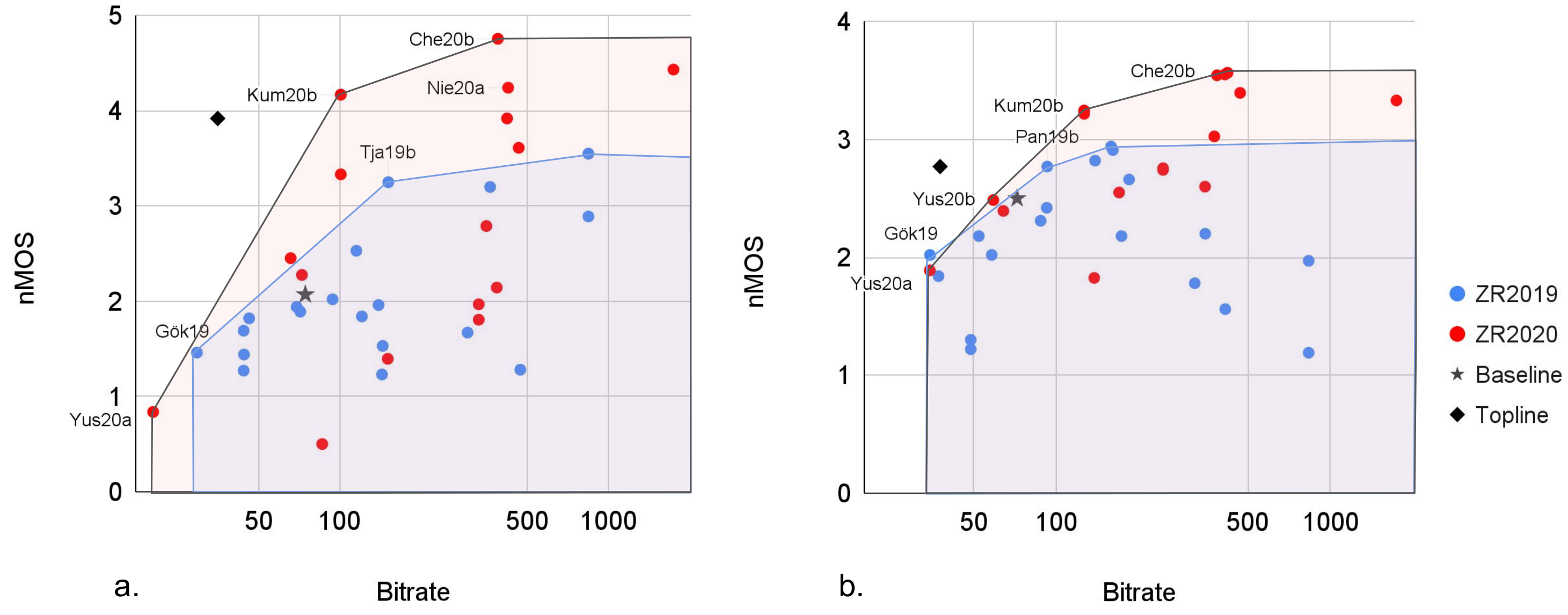
Fig. 5.
ZR Task 3 (TTS without T) human evaluation results on the surprise language (Indonesian, panel a) and the dev language (English, panel b) across the two editions of the Challenge (2019 and 2020). The nMOS score is obtained by normalizing the Mean Opinion Score across the two challenges by using the Baseline and Topline as anchor points.
Many of the systems that have a low bitrate (under 100b/sec) learn a discrete auto-encoder on acoustic features (Kam19a–b,Yus19,Gök19,Liu19a–b,Gün20), generally taking further steps such as filtering or down-sampling to reduce the temporal resolution. Taking a slightly different approach, our baseline model, as well as the related Yus20a–c, learn latent HMMs as acoustic units, in order to explicitly model duration. On the other hand, Pan19a–b,Kum20a,b put temporal reduction in an initial step of acoustic segmentation based on syllable-like units. Among these models, Kum20b, which presegments and then learns HMM acoustic units, stands out as reaching perfor- mance comparable to higher bitrate models (it admittedly has a somewhat higher bitrate than the other models listed here). Syllable-like presegmentation, as noted above, has also been used productively in Task 2 by Ras17, Alg22. It is fair to say that syllables have been underutilized in zero resource speech processing, given their promise.
Most of the remaining systems have a bitrate between 100 and 600b/sec. Supervised posteriorgrams are on the upper end of this, and MFCC representations have a bitrate around 15002. Most of the submitted systems in this range are compression approaches using discrete autoencoders, including the system of Che20b, which gives excellent performance. The system of Nie20a,b stands out among the others as yielding high quality results. This is the only submitted system which uses a predictive loss based on CPC—although, unlike typical CPC models, it works from spectrogram and is trained on the small (15h) dataset provided for the 2019 edition. The results of ( Citation: Lakhotia, Kharitonov & al., 2021 Lakhotia, K., Kharitonov, E., Hsu, W., Adi, Y., Polyak, A., Bolte, B., Nguyen, T., Copet, J., Baevski, A., Mohamed, A. & (2021). On generative spoken language modeling from raw audio. Transactions of the Association for Computational Linguistics, 9. 1336–1354. ) also support the claim that CPC and related approaches are well-adapted to discrete resynthesis (in addition to supporting entirely new tasks through their capacity to be used as language models3). Independently, ( Citation: 2021 Lakhotia, K., Kharitonov, E., Hsu, W., Adi, Y., Polyak, A., Bolte, B., Nguyen, T., Copet, J., Baevski, A., Mohamed, A. & (2021). On generative spoken language modeling from raw audio. Transactions of the Association for Computational Linguistics, 9. 1336–1354. ) demonstrated that an automatic evaluation using ASR is strongly predictive of human evaluators’ ratings.
example of citation : ( Citation: Dunbar, Algayres & al., 2019 Dunbar, E., Algayres, R., Karadayi, J., Bernard, M., Benjumea, J., Cao, X., Miskic, L., Dugrain, C., Ondel, L., Black, A. & (2019). The zero resource speech challenge 2019: TTS without T. Retrieved from https://arxiv.org/abs/1904.11469 )
Metrics
Intelligibility was measured by asking participants to or- thographically transcribe the synthesized sentence. Each tran- scription was compared with the gold transcription using the Levenshtein distance, yielding a Character Error Rate (CER). The overall naturalness of the synthesis was assessed on a 1 to 5 scale, yielding a Mean Opinion Score (MOS).4 Speaker similarity was assessed using a 1 to 5 scale.
Sentences were presented in pairs (target voice, system voice)5. A training phase occurred before each task. Three “catch” trials were included in the transcription, consisting of easy sentences from the original corpus not included in the rest of the experimental list, allowing us to detect participants that failed to do the task.
Each participant performed the evaluation tasks in the same order (Intelligibility, Naturalness, Similarity), the overall evaluation lasting about one hour. To avoid re-evaluation of the same sentence by the same participant, the sentences (types) were split into two disjoint subsets: one third for the Intelligibility task (62 for English, 49 for Indonesian), and two third for the Naturalness task (129 for English, 100 for Indonesian). The complete set of sentences was used in the Similarity task. In the Intelligibility and Naturalness tasks, all the sentences were seen by all subjects; in the Similarity task, a pseudo random one-third of the whole sentences was selected for each participant. Each sentence token was evaluated at least once with each system (the submitted, topline and baseline systems, as well as the original recordings)6. English judges were recruited through Mechanical Turk. Indonesian judges were recruited through universities and research institutes in Indonesia. All were paid the equivalent of 10 USD. Only data from participants with <0.80 CER on catch trials were retained (Development: 35/35; Surprise: 68/69).
For the bitrate computation, each vector is processed as a character string. A dictionary of the possible values is constructed over the embedding file for the submitted test set. We thus assume that the entire test set corresponds to a sequence of vectors U of length $n$: $U=[s_1,…,s_n]$ The bit rate for $U$ is then $B(U)=n \sum_{i=1}^{n}{\frac{p(s_i)log_{2}p(s_i)}{D}}$, where $p(s_i)$ is the probability of symbol $s_i$. The numerator is $n$ times the entropy of the symbols, which gives the optimal number of bits needed to transmit the sequence of symbols $s_{1:n}$. To obtain a bitrate, we divide by $D$, the total duration of $U$ in seconds 7.
Bibliography
$^*$The full bibliography can be found here
- Scharenborg, Besacier, Black, Hasegawa-Johnson, Metze, Neubig, Stüker, Godard, Müller, Ondel, Palaskar, Arthur, Ciannella, Du, Larsen, Merkx, Riad, Wang & Dupoux (2018)
- Scharenborg, O., Besacier, L., Black, A., Hasegawa-Johnson, M., Metze, F., Neubig, G., Stüker, S., Godard, P., Müller, M., Ondel, L., Palaskar, S., Arthur, P., Ciannella, F., Du, M., Larsen, E., Merkx, D., Riad, R., Wang, L. & Dupoux, E. (2018). Linguistic unit discovery from multi-modal inputs in unwritten languages: Summary of the “speaking rosetta” JSALT 2017 workshop. IEEE.
- Dunbar, Algayres, Karadayi, Bernard, Benjumea, Cao, Miskic, Dugrain, Ondel, Black & (2019)
- Dunbar, E., Algayres, R., Karadayi, J., Bernard, M., Benjumea, J., Cao, X., Miskic, L., Dugrain, C., Ondel, L., Black, A. & (2019). The zero resource speech challenge 2019: TTS without T. Retrieved from https://arxiv.org/abs/1904.11469
- Kharitonov, Rivière, Synnaeve, Wolf, Mazaré, Douze & Dupoux (2021)
- Kharitonov, E., Rivière, M., Synnaeve, G., Wolf, L., Mazaré, P., Douze, M. & Dupoux, E. (2021). Data augmenting contrastive learning of speech representations in the time domain. IEEE.
- Lakhotia, Kharitonov, Hsu, Adi, Polyak, Bolte, Nguyen, Copet, Baevski, Mohamed & (2021)
- Lakhotia, K., Kharitonov, E., Hsu, W., Adi, Y., Polyak, A., Bolte, B., Nguyen, T., Copet, J., Baevski, A., Mohamed, A. & (2021). On generative spoken language modeling from raw audio. Transactions of the Association for Computational Linguistics, 9. 1336–1354.
-
In this challenge, the embedding files do not have any notion of frames or timestamps. This is because we allow participants to submit representations of length shorter than the number of frames, rather than forcing them to duplicate repeated units in the embedding file. Without time alignment, this challenge used a version of ABX in which the systems are fed short waveforms corresponding to each test triphone, rather than, as in other Task 1 evaluations, feeding them entire utterances from which the embeddings for the triphones is extracted using the time alignments. This may penalize systems that have not been trained to encode very short speech segments. ↩︎
-
Note that our bitrates are calculated empirically on a rather small speech corpus. The representational capacity of MFCC representations is an order of magnitude higher. ↩︎
-
Combining Task 3 and Task 4 leads us to consider the possibility of generating spoken language. A traditional spo- ken dialogue system will (conditional on some knowledge source) generate text, typically using a neural language model. The text is then synthesized into speech. A spoken language model can be made to generate spoken language directly, as demonstrated by ( Citation: Lakhotia, Kharitonov & al., 2021 Lakhotia, K., Kharitonov, E., Hsu, W., Adi, Y., Polyak, A., Bolte, B., Nguyen, T., Copet, J., Baevski, A., Mohamed, A. & (2021). On generative spoken language modeling from raw audio. Transactions of the Association for Computational Linguistics, 9. 1336–1354. ; Citation: Kharitonov, Rivière & al., 2021 Kharitonov, E., Rivière, M., Synnaeve, G., Wolf, L., Mazaré, P., Douze, M. & Dupoux, E. (2021). Data augmenting contrastive learning of speech representations in the time domain. IEEE. ) . Much as Task 3 is complementary to Task 1—but has slightly different constraints—the task of generating speech from a spoken language model will be developed into a Task 5. Following ( Citation: 2021 Lakhotia, K., Kharitonov, E., Hsu, W., Adi, Y., Polyak, A., Bolte, B., Nguyen, T., Copet, J., Baevski, A., Mohamed, A. & (2021). On generative spoken language modeling from raw audio. Transactions of the Association for Computational Linguistics, 9. 1336–1354. ) , we may make use of the fact that human evaluations of the intelligibility and meaningfulness of the generated speech can be estimated using ASR-based proxy measurements (Phone Error Rate for intelligibility in a Task 3 setting, and continuation BLEU or VERT score for the prompted or unmprompted generations). ↩︎
-
The question posed was: Rate how natural the audio is, between 1 and 5 (1=very unnatural, 3 = neutral, 5=very natural). ↩︎
-
The question posed was: Rate the similarity between the reference voice and the system voice, between 1 and 5 (1 = very different voices, 3 = neither similar nor different voices, 5 = very similar voices). Ten additional trials were included, for each participant, in which the reference voice was not the target voice but the source voice. ↩︎
-
In the Intelligibility task, each system was evaluated at least 70 times for English, and 148 times for Indonesian, with each combination of sentence and system seen at least once. In the Naturalness task, each system was evaluated at least 180 times for English, and 274 for Indonesian, with each combination of sentence and system seen at least 36 times for English and at least 68 times for Indonesian. In the Similarity task, each system was evaluated at least 89 times in English, and 120 times in Indonesian, and all possible combinations of sentence and system were seen by at least one participant. ↩︎
-
A fixed frame rate transcription may have a higher bitrate than a “textual” representation due to the repetition of symbols across frames. For instance, the bitrate of a 5 ms framewise gold phonetic transcription is around 450 bits/sec and that of a “textual” transcription around 60 bits/sec. ↩︎
